Klausurzusammenfassung: Statistik 2
Fortgeschrittene Stochastik und Statistik: Verteilungen, induktive Tests, OLS-Regression, Regressionsprobleme und Maximum-Likelihood-Schätzung
1. Überblick und Klausurlogik
Statistik 2 wechselt von deskriptiven Kennzahlen zu Verteilungen, Stichprobenschlüssen und Modellschätzung. Die Klausurfrage ist selten nur: „Welche Formel passt?“. Entscheidend ist die Reihenfolge: Datentyp erkennen, Verteilungsannahme prüfen, Hypothesen sauber formulieren, Test oder Modell wählen, Kennzahlen korrekt interpretieren und die Grenzen der Aussage benennen.
Gliederung
- Zufallsvariablen und Verteilungsfunktionen
- Momente: Erwartungswert, Varianz, Schiefe und Wölbung
- Ausgewählte Verteilungen und Modellierung
- Normalverteilung und zentraler Grenzwertsatz
- Induktive Statistik, Z-Test und Testauswahl
- t-Test, Konfidenzintervalle und ANOVA
- Normalität, nichtparametrische Alternativen und Testfehler
- Chi-Quadrat-Testfamilie
- Lineare Regression und OLS-Schätzung
- Multikollinearität, Endogenität und Overfitting
- Maximum-Likelihood-Schätzung
- Codebeispiele aus den Notebooks
- Klausurstrategie, Checkliste und mögliche Fragen
- Abdeckung des Foliensatzes
2. Zufallsvariablen und Verteilungsfunktionen
2.1 Zufallsvariable als Abbildung
Eine Zufallsvariable ist eine Abbildungsvorschrift, die jedem Ereignis aus der Ereignismenge Ω eine reelle Zahl zuordnet. Ist das Ereignis selbst schon numerisch, kann die Abbildung direkt sein, etwa beim Würfel. Ist das Ereignis kategorial, muss eine sinnvolle Codierung gewählt werden, etwa Kopf = 0 und Zahl = 1.
- X
- Zufallsvariable bzw. Abbildungsvorschrift.
- Ω
- Ereignismenge, z. B. alle Würfelergebnisse oder alle Roulettefelder.
- E
- Wertebereich der Zufallsvariable, also die möglichen reellen Ausprägungen.

2.2 Diskret oder kontinuierlich
| Typ | Eigenschaft | Funktion für „genau x“ | Funktion für „höchstens x“ |
|---|---|---|---|
| Diskret | Endlich oder abzählbar unendlich viele Werte. | f(x) = P(X = x) | F(x) = P(X ≤ x) |
| Kontinuierlich | Nicht abzählbar viele Werte in Intervallen. | Keine Punktwahrscheinlichkeit; P(X=x)=0. | F(x) = P(X ≤ x), berechnet über die Dichte. |
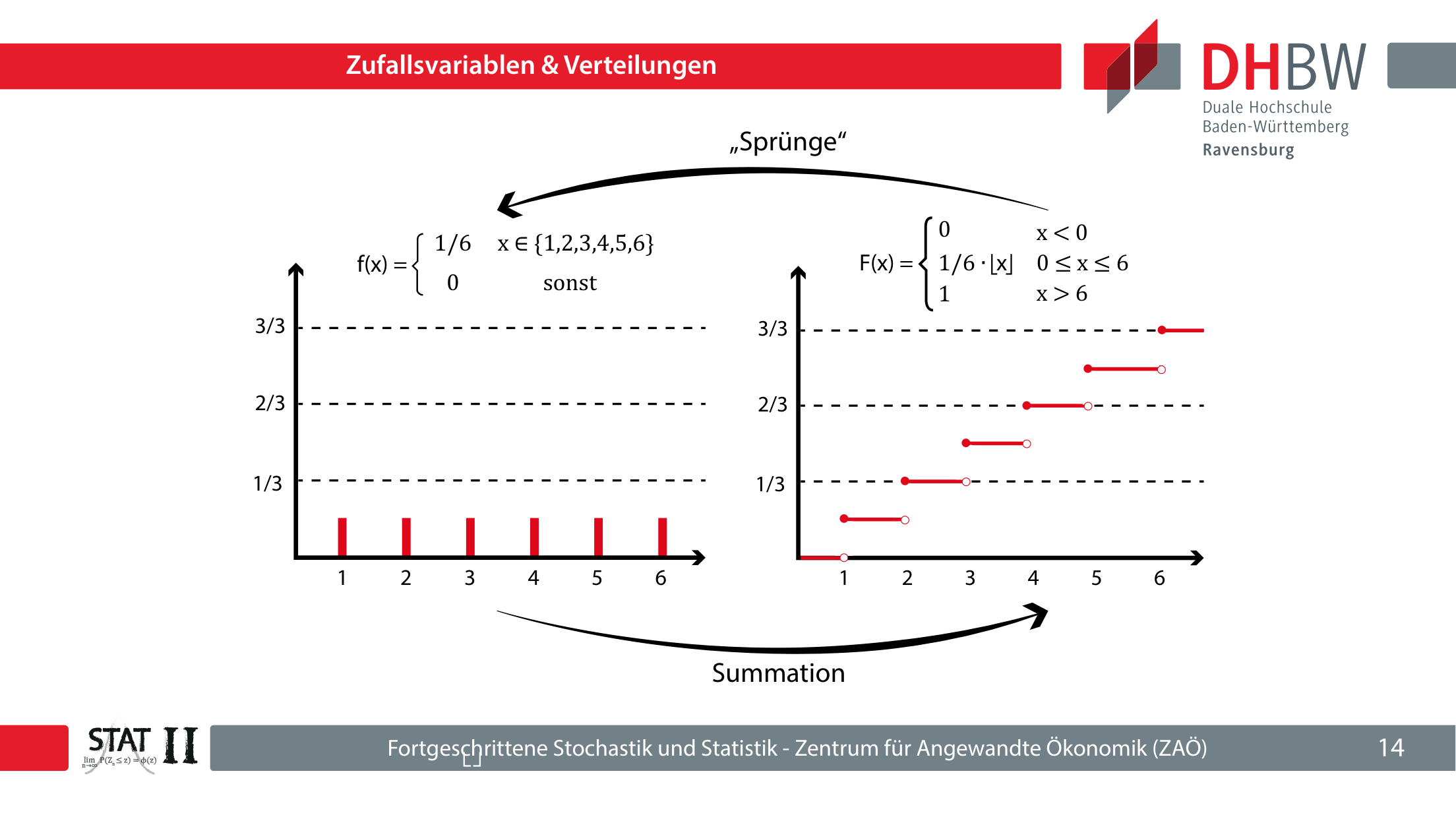
Beispiel Würfel: f(x)=1/6 für x∈{1,2,3,4,5,6}, sonst 0.
Beim Würfel ist F(x) eine Treppenfunktion. Bei jedem zulässigen Wert steigt sie um dessen Wahrscheinlichkeit.
2.3 Kontinuierliche Verteilungen
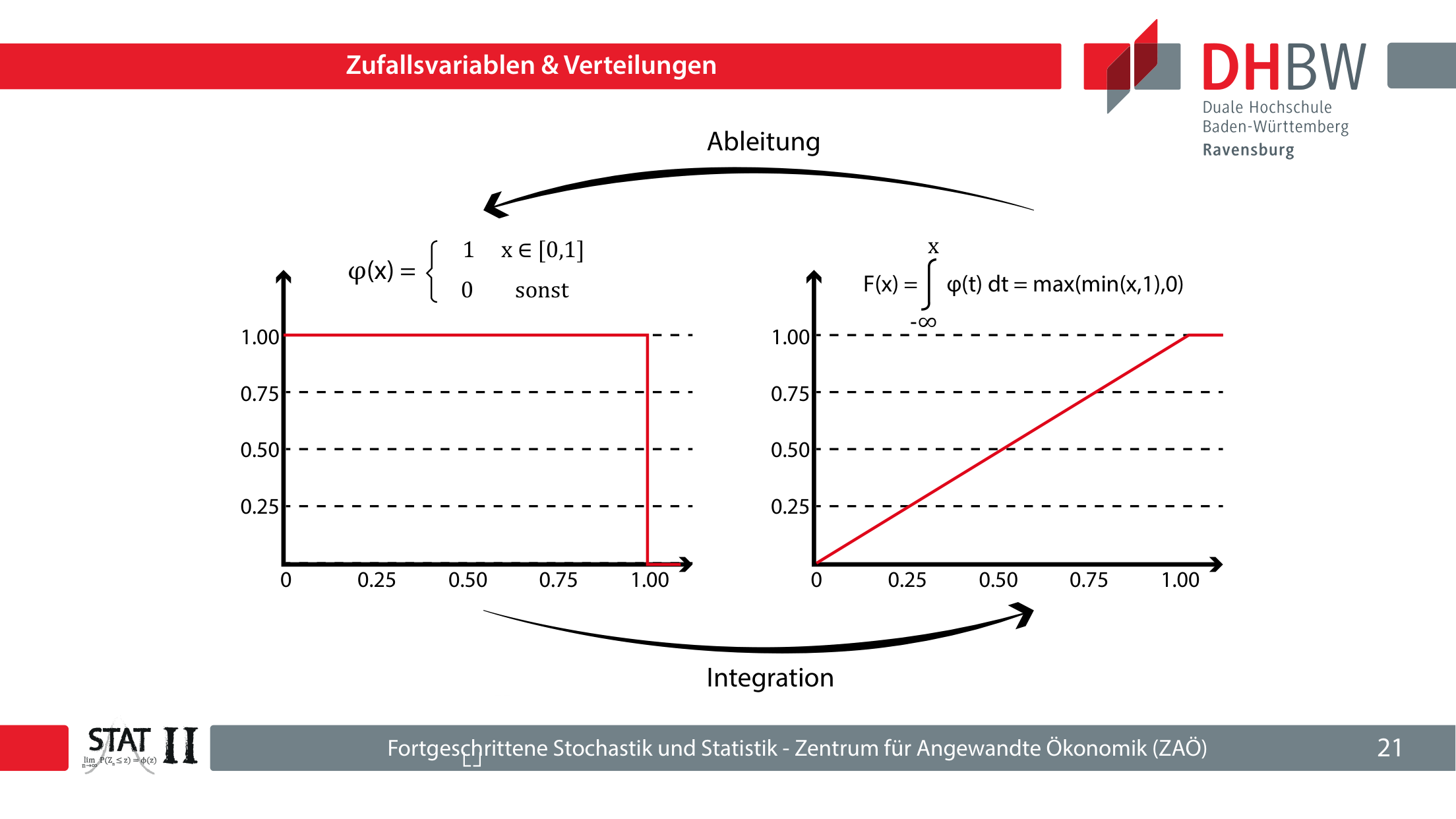
Bei kontinuierlichen Verteilungen beschreibt die Dichtefunktion φ(x) keine Wahrscheinlichkeit für den Einzelwert x. Wahrscheinlichkeiten entstehen erst als Fläche unter der Dichtekurve über einem Intervall.
Die Gesamtfläche muss 1 ergeben: ∫-∞∞ φ(x) dx = 1.
Die Dichte ist die Ableitung der Verteilungsfunktion, soweit diese differenzierbar ist.
3. Momente von Zufallsvariablen
3.1 Erwartungswert
Der Erwartungswert μ bzw. E(X) ist der Schwerpunkt einer Verteilung. Er ist nicht zwingend ein Wert, den die Zufallsvariable tatsächlich annehmen kann. Beim fairen Würfel ist der Erwartungswert 3,5, obwohl keine 3,5 gewürfelt werden kann.
Würfel: (1+2+3+4+5+6)/6 = 3,5.
Gleichverteilung auf [0,1]: ∫01x dx = 0,5.
Diese Linearität gilt unabhängig davon, ob X und Y unabhängig sind.
3.2 Varianz und Standardabweichung
Die Varianz misst die erwartete quadrierte Abweichung vom Erwartungswert. Die Standardabweichung σX ist die Wurzel der Varianz und wieder in der Einheit der Zufallsvariable interpretierbar.
Nur bei unabhängigen Zufallsvariablen ist die Kovarianz 0. Dann addieren sich die Varianzen gewichtet mit den quadrierten Faktoren.
3.3 Höhere Momente
Momente verallgemeinern Erwartungswert und Varianz. Der Erwartungswert ist das erste Moment, die Varianz das zweite zentrale Moment. Das dritte zentrale Moment beschreibt Schiefe, das vierte zentrale Moment Wölbung bzw. Exzess.

| Größe | Formelidee | Interpretation |
|---|---|---|
| Moment mk | E(Xk) | Rohmoment um 0. |
| Zentrales Moment μk | E((X-μ)k) | Moment um den Erwartungswert. |
| Schiefe | γ = μ3 / σ3 | γ=0 symmetrisch, γ>0 rechtsschief, γ<0 linksschief. |
| Exzess | γ = μ4 / σ4 - 3 | Vergleich der Wölbung mit der Normalverteilung. |
4. Ausgewählte Verteilungen und Modellierung
4.1 Gleichverteilung
Die kontinuierliche Gleichverteilung auf dem Intervall [a,b] hat eine konstante Dichte. Sie eignet sich, wenn alle Werte in einem Intervall gleich plausibel sind.
a ist die Untergrenze, b die Obergrenze.
4.2 Binomialverteilung
Die Binomialverteilung beschreibt die Anzahl k erfolgreicher Versuche in n unabhängigen Versuchen mit konstanter Erfolgswahrscheinlichkeit p. Typische Klausurindikatoren sind „aus n Versuchen genau/mindestens/höchstens k Erfolge“.
- n
- Anzahl unabhängiger Versuche.
- k
- Anzahl Erfolge.
- p
- Erfolgswahrscheinlichkeit je Versuch.
4.3 Poisson-Verteilung
Die Poisson-Verteilung modelliert die Anzahl von Ereignissen in einem festen Zeitraum oder Raum, wenn die durchschnittliche Rate λ bekannt ist. Sie ist ein Grenzfall der Binomialverteilung bei vielen Versuchen und kleiner Erfolgswahrscheinlichkeit.
λ ist die erwartete Anzahl Ereignisse pro betrachteter Einheit, z. B. IT-Probleme pro Stunde.
4.4 Exponentialverteilung
Die Exponentialverteilung modelliert Wartezeiten zwischen Ereignissen eines Poisson-Prozesses. Sie ist gedächtnislos: Wer schon lange gewartet hat, hat dadurch keine höhere oder niedrigere Restwartewahrscheinlichkeit.
5. Normalverteilung und zentraler Grenzwertsatz
5.1 Normalverteilung
Die Normalverteilung ist zentral, weil viele natürliche Merkmale annähernd normalverteilt sind und weil Stichprobenmittelwerte unter breiten Bedingungen näherungsweise normalverteilt werden. Sie wird durch Erwartungswert μ und Varianz σ2 parametrisiert.
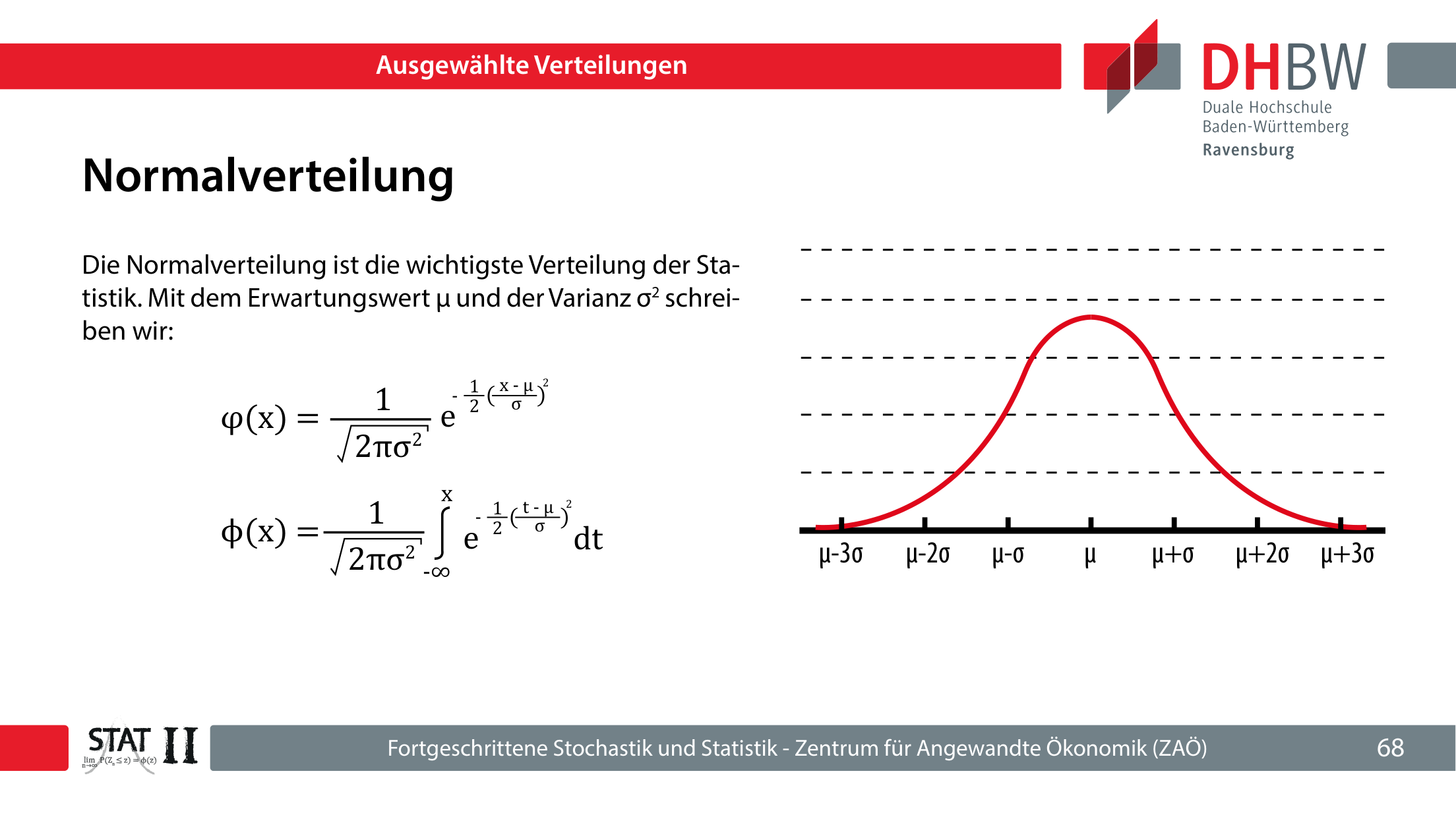
- μ
- Erwartungswert, Lagezentrum.
- σ
- Standardabweichung, Streuung.
- σ2
- Varianz.
5.2 Zentraler Grenzwertsatz
Der zentrale Grenzwertsatz besagt: Summen und Mittelwerte vieler unabhängiger, identisch verteilter Zufallsvariablen werden näherungsweise normalverteilt. Für die Summe addieren sich Erwartungswerte und Varianzen. Für den Mittelwert bleibt der Erwartungswert gleich, die Varianz schrumpft mit 1/n.
Als Faustregel nennt der Foliensatz etwa n≥30, bei schwierigen Einzelverteilungen eher n≥100. Diese Zahl ist keine Garantie, sondern eine praktische Orientierung.
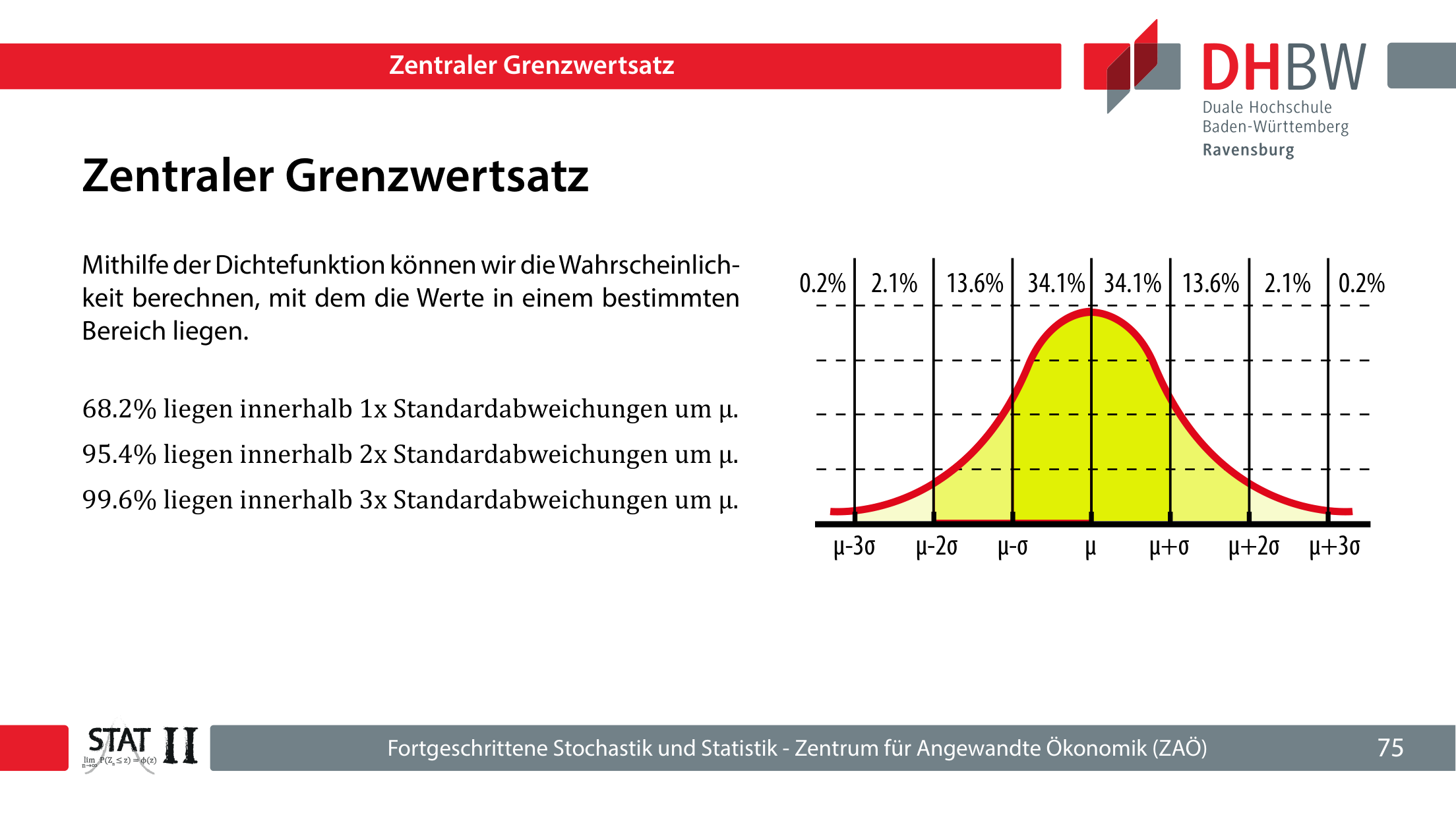
| Bereich um μ | Wahrscheinlichkeit | Klausurbedeutung |
|---|---|---|
| ±1σ | ca. 68,2 % | Normale Abweichung, selten signifikant. |
| ±1,96σ | ca. 95 % | Zweiseitige 5 %-Schwelle. |
| ±2,32σ | ca. 99 % | Zweiseitige 1 %-Schwelle. |
| ±3,09σ | ca. 99,9 % | Sehr extreme Abweichung. |
6. Induktive Statistik, Z-Test und Testauswahl
6.1 Grundidee induktiver Tests
Induktive Statistik schließt von einer Stichprobe auf die Grundgesamtheit. Ein statistischer Test prüft ein Hypothesenpaar. Die Nullhypothese H0 ist die Ausgangsannahme; die Alternativhypothese H1 beschreibt die Abweichung, die nachgewiesen werden soll.
6.2 Z-Test
Der Z-Test wird eingesetzt, wenn die Verteilung unter der Nullhypothese, insbesondere Erwartungswert und Varianz, theoretisch bekannt ist oder durch den ZGS ausreichend bestimmt werden kann. Im Würfelbeispiel ist die Augenzahl theoretisch gleichverteilt mit μ=3,5 und σ2=2,91.
- x̄
- Stichprobenmittelwert.
- μ0
- Erwartungswert unter der Nullhypothese.
- σ/√n
- Standardfehler des Mittelwerts.
| Testart | Alternativhypothese | p-Wert-Bereich |
|---|---|---|
| Linksseitig | μ<μ0 | Linke Fläche unter der Standardnormalverteilung. |
| Rechtsseitig | μ>μ0 | Rechte Fläche unter der Standardnormalverteilung. |
| Zweiseitig | μ≠μ0 | Beide Extrembereiche; bei symmetrischer Verteilung typischerweise doppelte einseitige Fläche. |
6.3 Welche Tests gibt es?
Der Foliensatz unterscheidet Verteilungshypothesen, Parameterhypothesen und Abhängigkeitshypothesen. Die Testwahl hängt von abhängiger Variable, Skalenniveau, Anzahl der Gruppen, Paarung der Stichproben, Verteilungsannahmen und Stichprobengröße ab.
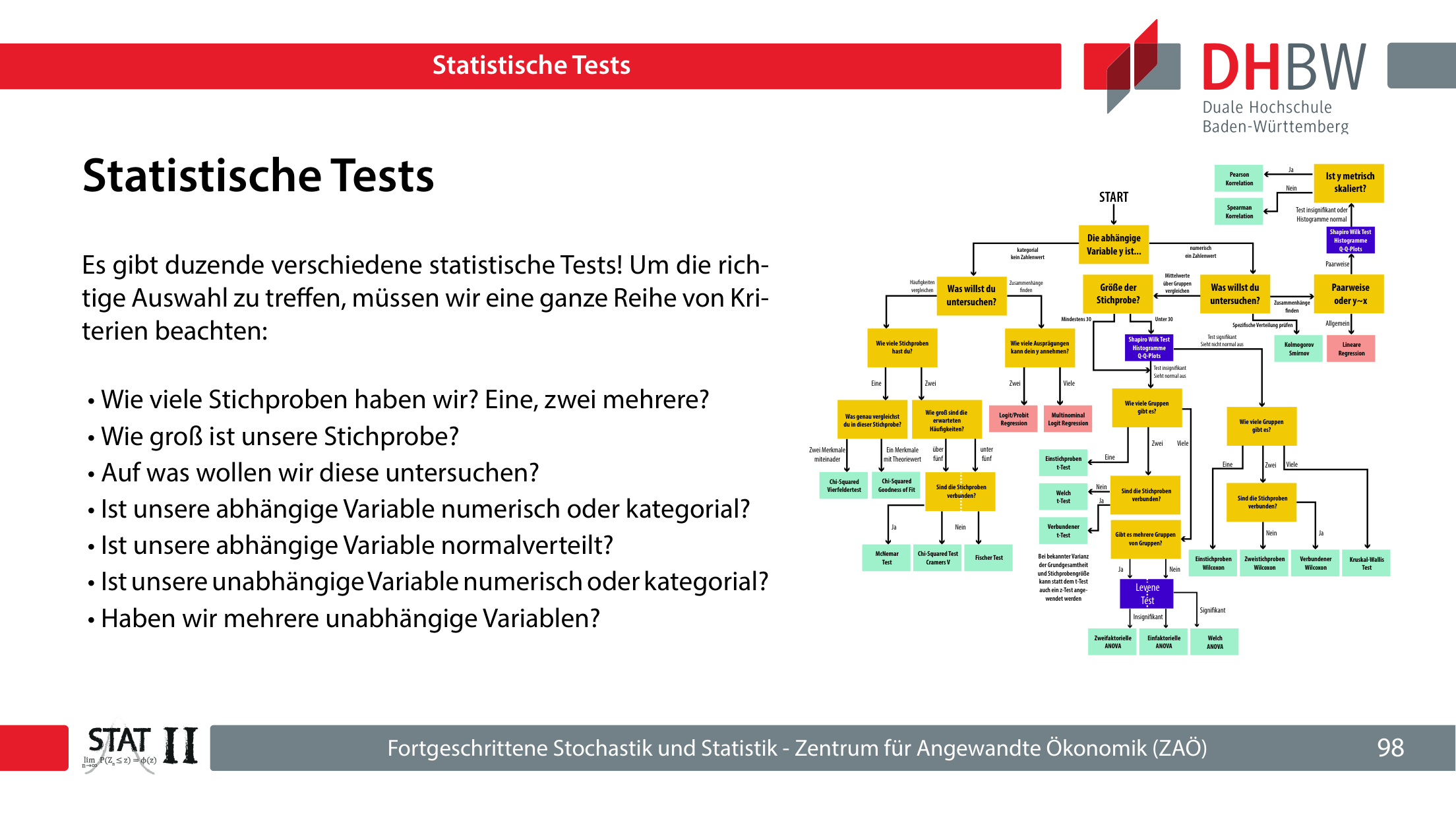
7. t-Test, Konfidenzintervalle und ANOVA
7.1 Warum t statt z?
Beim t-Test ist die Varianz der Grundgesamtheit unbekannt und wird aus der Stichprobe geschätzt. Diese zusätzliche Unsicherheit wird durch die Studentsche t-Verteilung abgebildet. Mit steigender Zahl an Freiheitsgraden nähert sie sich der Normalverteilung an.
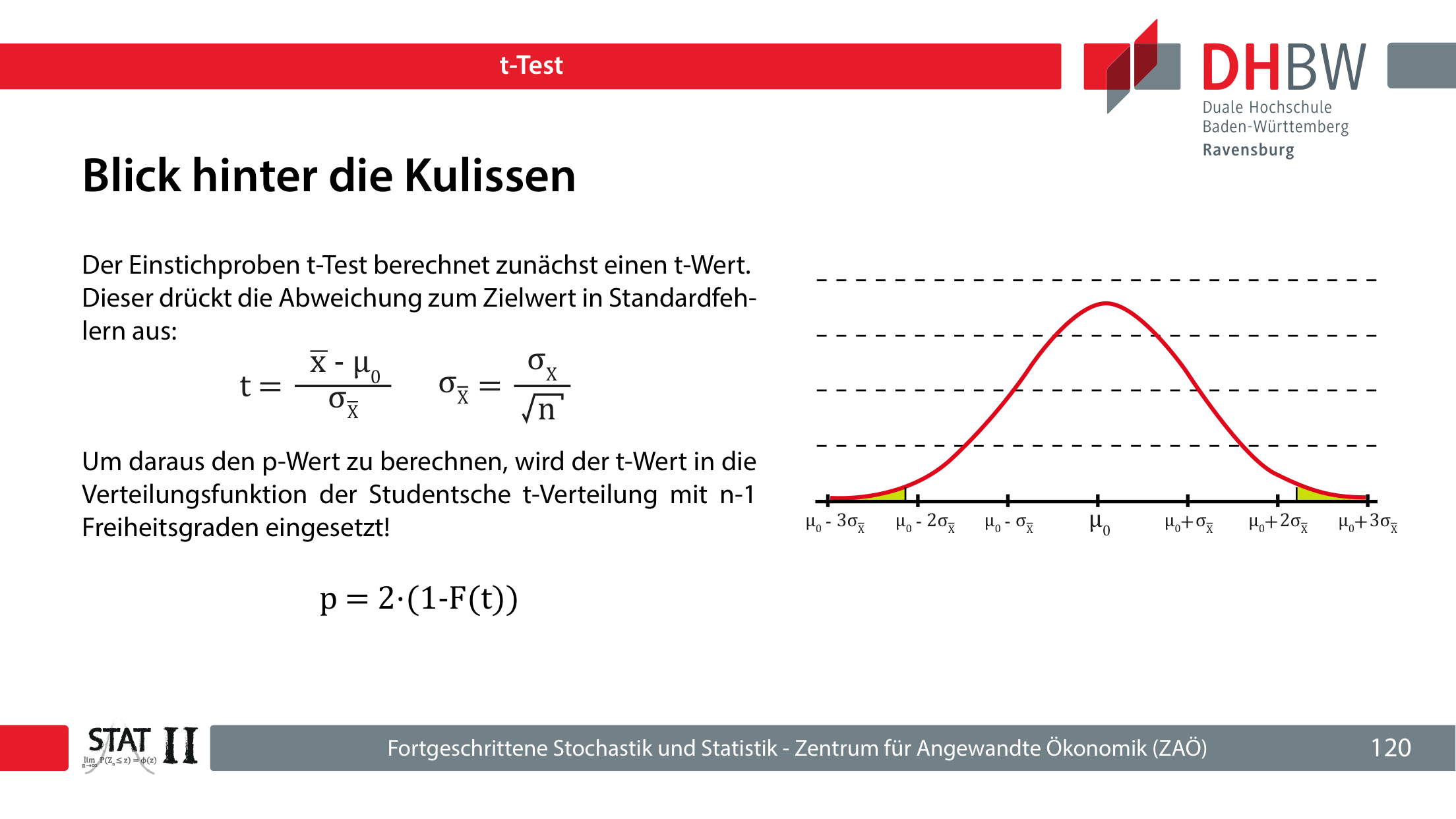
Getestet wird, ob der wahre Mittelwert einem Zielwert μ0 entspricht. Beim Bierbeispiel führt p=0,0406 und ein 95 %-Konfidenzintervall von [4,004; 4,185] zur Verwerfung des Sollwerts 4,000.
7.2 Zwei Stichproben und Paarung
| Fall | Beispiel aus Folien | Testlogik |
|---|---|---|
| Nicht gepaart | Leistung von WI- und Data-Science-Studierenden. | Die Beobachtungen sind unterschiedliche Personen. Die Gruppenmittelwerte werden getrennt verglichen. |
| Gepaart | Marketing- und Analysis-Leistung derselben Personen. | Die Differenzen innerhalb derselben Person sind relevant; die Paarung senkt störende Individualunterschiede. |
7.3 p-Wert und Konfidenzintervall zusammen lesen
Ein Konfidenzintervall zeigt plausible Werte des wahren Unterschieds. Enthält ein zweiseitiges 95 %-Konfidenzintervall die 0 nicht, ist der zugehörige p-Wert kleiner als 5 %. Enthält es die 0, ist ein echter Unterschied auf diesem Niveau nicht nachgewiesen.
7.4 ANOVA
Die ANOVA erweitert die Mittelwertvergleiche auf mehr als zwei Gruppen. Sie prüft zunächst nur, ob mindestens ein Gruppenmittelwert von mindestens einem anderen abweicht. Welche Gruppen sich unterscheiden, klären Post-Hoc-Tests.
g ist die Anzahl der Gruppen.

8. Normalität, Alternativen und Testfehler
8.1 Voraussetzungen parametrischer Tests
t-Tests und ANOVA sind parametrische Tests. Für den t-Test müssen die Daten metrisch skaliert sein, und der Mittelwert der Stichprobe muss näherungsweise normalverteilt sein. Bei größeren Stichproben wird diese Voraussetzung durch den zentralen Grenzwertsatz oft praktikabel; bei kleinen Stichproben muss genauer geprüft werden.
| Problem | Mögliche Alternative |
|---|---|
| Zwei ungepaarte Stichproben, Normalitätsannahme fraglich | Wilcoxon-Rangsummen-Test oder Mann-Whitney-U-Test |
| Zwei gepaarte Stichproben, Normalitätsannahme fraglich | Wilcoxon-Vorzeichen-Rang-Test |
| Median gegen Zielwert | Sign-Test |
8.2 Q-Q-Plot und Normalitätstests
Histogramme hängen stark von der Klasseneinteilung ab. Q-Q-Plots vergleichen die sortierten Stichprobenwerte mit den theoretischen Quantilen der Normalverteilung und sind für kleine Stichproben oft informativer.
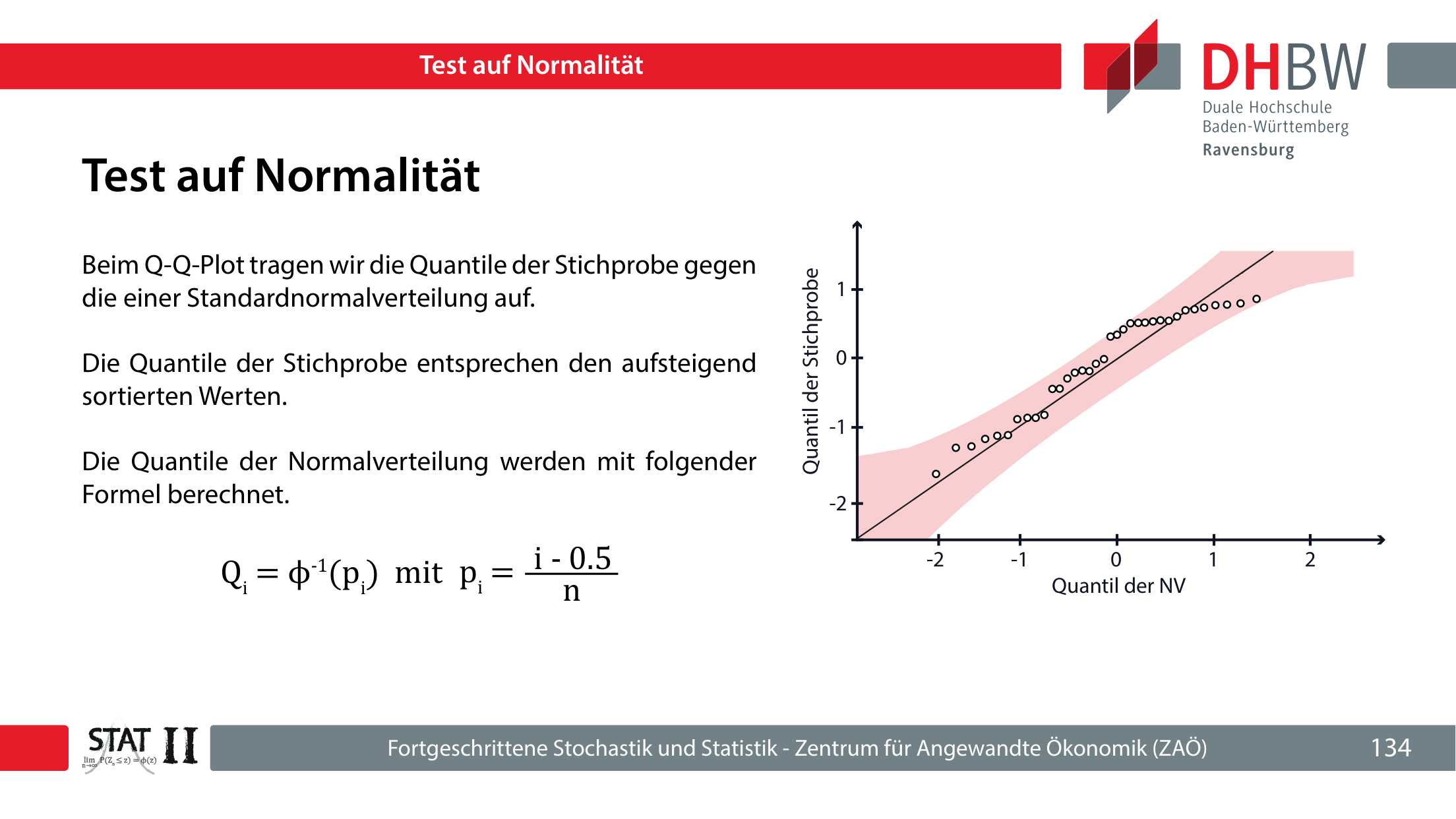
Φ-1 ist die inverse Verteilungsfunktion der Standardnormalverteilung.
Formale Normalitätstests sind Shapiro-Wilk, Kolmogorov-Smirnov und Anderson-Darling. Die Nullhypothese lautet: Die Grundgesamtheit folgt der geprüften Verteilung. Für Normalität will man deshalb typischerweise keinen kleinen p-Wert.
8.3 Fehlerarten
| Fehler | Bedeutung | Auch bekannt als |
|---|---|---|
| Fehler erster Art | H0 wird verworfen, obwohl sie wahr ist. | Falsch positiv; Wahrscheinlichkeit entspricht dem Signifikanzniveau. |
| Fehler zweiter Art | H0 wird nicht verworfen, obwohl sie falsch ist. | Falsch negativ. |
| Datenfehler | Messdaten sind selbst fehlerhaft. | Qualitätsproblem der Datenerhebung. |
| Modellfehler | Ungeeigneter Test oder verletzte Verteilungsannahmen. | Methodenproblem. |
9. Chi-Quadrat-Testfamilie
9.1 Unabhängigkeitstest
Der Chi-Quadrat-Unabhängigkeitstest prüft, ob zwei kategoriale Merkmale unabhängig sind. Er vergleicht die beobachtete Kontingenztabelle mit der erwarteten Tabelle unter H0.
- Oij
- Beobachtete Häufigkeit in Zelle i,j.
- Eij
- Erwartete Häufigkeit unter Unabhängigkeit.
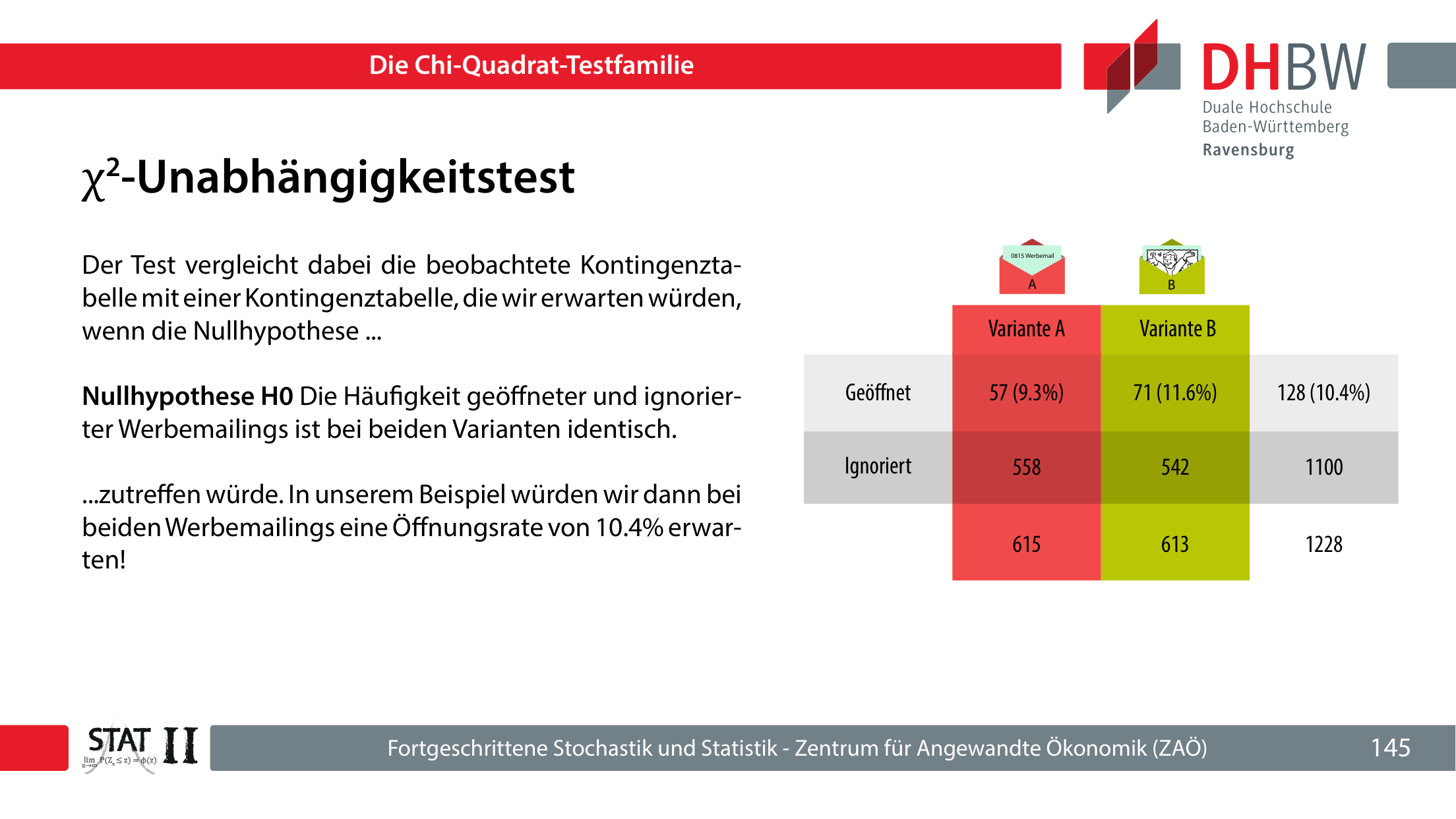
Im Werbemailing-Beispiel ergibt der Unabhängigkeitstest einen p-Wert von 0,2174. Ein Unterschied der Öffnungsraten von 9,27 % zu 11,58 % ist unter H0 plausibel; die Nullhypothese wird beibehalten.
9.2 Anpassungstest
Der Chi-Quadrat-Anpassungstest prüft, ob die beobachtete Verteilung eines kategorialen Merkmals zu einer erwarteten Verteilung passt. Im Studiengangsbeispiel führt ein p-Wert von 0,00808 zur Verwerfung: Das Sample weicht signifikant von der erwarteten Grundverteilung ab.
| Test | Fragestellung | Nullhypothese |
|---|---|---|
| Unabhängigkeitstest | Hängen zwei kategoriale Merkmale zusammen? | Die Merkmale sind unabhängig. |
| Anpassungstest | Passt eine beobachtete Häufigkeitsverteilung zu einer erwarteten Verteilung? | Die beobachtete Verteilung passt zur erwarteten. |
10. Lineare Regression und OLS-Schätzung
10.1 Regression als Zusammenhangsmodell
Regression sucht Zusammenhänge zwischen abhängigen und unabhängigen Variablen. Bei der linearen OLS-Regression werden Koeffizienten so gewählt, dass die Summe der quadrierten Residuen minimal wird.
- yi
- Abhängige Variable für Beobachtung i.
- β0
- Achsenabschnitt; erwarteter Wert bei x=0.
- β1
- Steigung; durchschnittliche Änderung von y bei einer zusätzlichen Einheit x.
- εi
- Störterm; alle nicht modellierten Einflüsse.
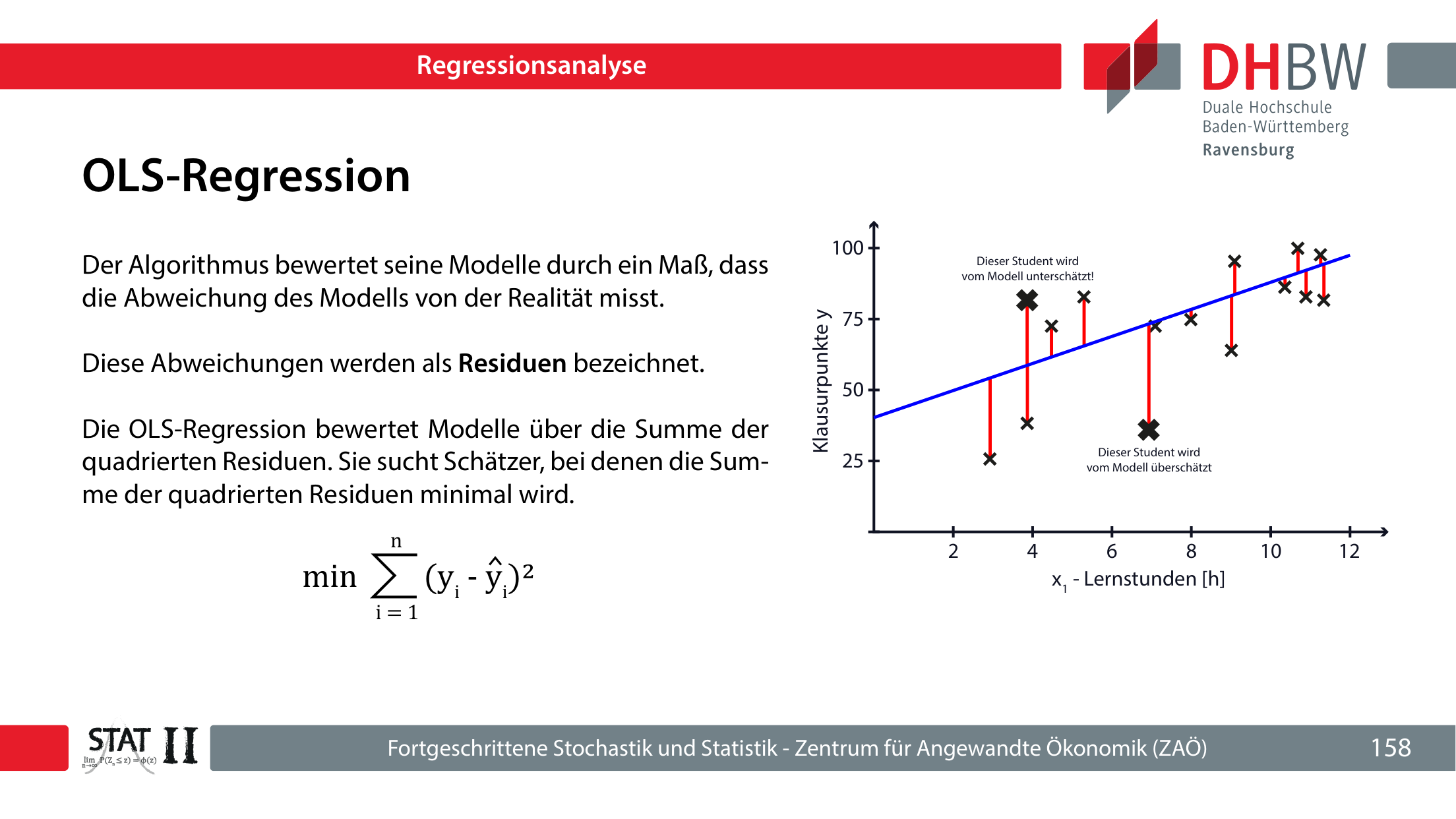
ŷi ist der durch das Modell geschätzte Wert.
10.2 Output interpretieren
| Outputgröße | Bedeutung | Interpretation |
|---|---|---|
| Schätzer β̂k | Geschätzter Effekt der unabhängigen Variable. | Beim Lernstundenbeispiel: Eine Lernstunde mehr ist mit ca. 4,534 Punkten mehr assoziiert. |
| Standardfehler | Unsicherheit des Schätzers. | Je größer, desto weniger präzise ist der geschätzte Effekt. |
| t-Wert und p-Wert | Test gegen H0: βk=0. | Kleiner p-Wert spricht gegen „kein Zusammenhang“. |
| Konfidenzintervall | Plausibler Bereich für den wahren Koeffizienten. | Enthält es 0 nicht, ist der Effekt auf dem zugehörigen Niveau signifikant. |
| R2, korrigiertes R2 | Erklärter Varianzanteil. | Korrigiertes R2 bestraft zusätzliche Variablen. |
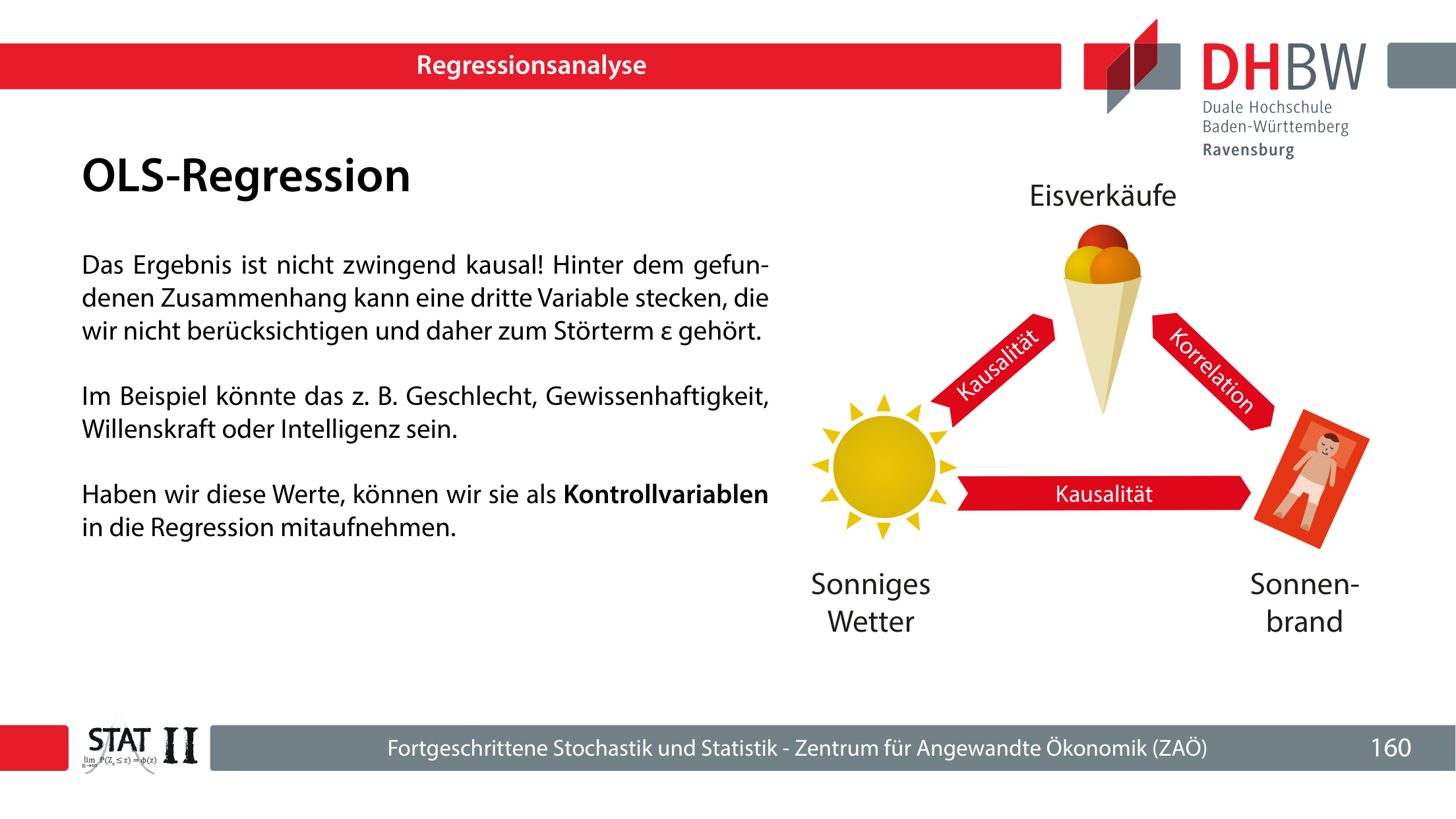
10.3 Korrelation ist nicht Kausalität
OLS zeigt zunächst Assoziationen. Ein signifikanter Koeffizient beweist keinen kausalen Effekt. Dritte Variablen können gleichzeitig unabhängige und abhängige Variable beeinflussen und damit eine Scheinkorrelation erzeugen.
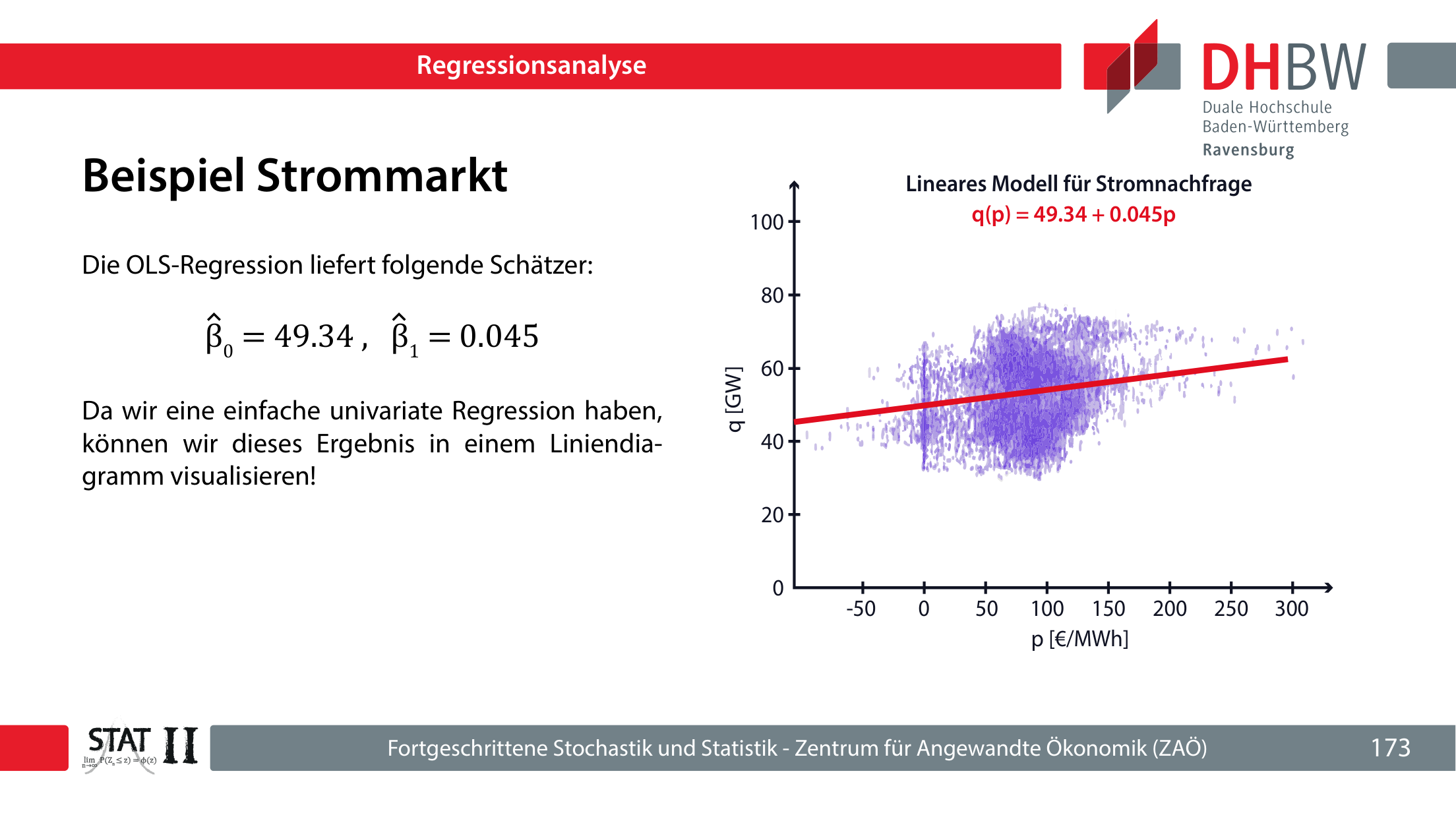
10.4 Strommarktbeispiel
Im Strommarktbeispiel wirkt eine einfache Regression der Nachfrage auf den Strompreis zunächst statistisch signifikant, aber fachlich falsch gerichtet: Eine höhere Nachfrage treibt eher den Preis, nicht umgekehrt. Erst das Modell mit Preis als abhängiger Variable, Nachfrage und erneuerbarer Einspeisung als unabhängigen Variablen ist ökonomisch plausibler.
10.5 Residuenprüfung
Residuen sind die Abweichungen zwischen beobachtetem und geschätztem Wert. Sie sollten insbesondere auf Normalverteilung und Homoskedastizität geprüft werden. Homoskedastizität bedeutet, dass die Streuung der Residuen nicht systematisch mit dem geschätzten Wert zunimmt oder abnimmt.
11. Multikollinearität, Endogenität und Overfitting
11.1 Multikollinearität
Multikollinearität liegt vor, wenn unabhängige Variablen stark miteinander korrelieren. Das Modell kann y weiterhin gut erklären, aber die einzelnen Koeffizienten werden instabil, haben hohe Standardfehler und können fachlich unsinnig wirken. Der Schätzer kann weiterhin erwartungstreu sein, aber der zufällige Schätzfehler ist groß.
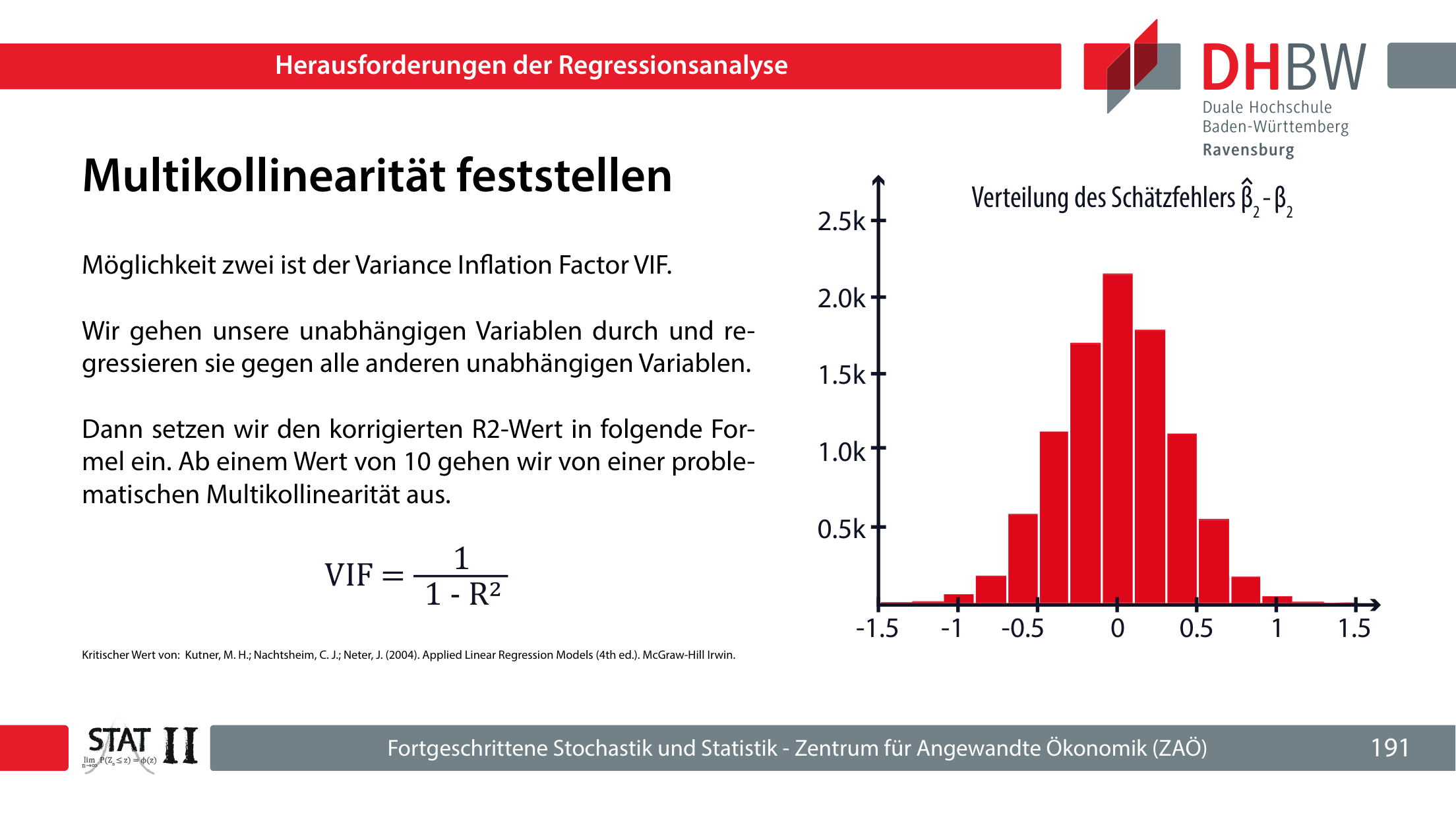
Für jede unabhängige Variable wird sie auf die übrigen unabhängigen Variablen regressiert. Ab etwa 10 wird Multikollinearität im Foliensatz als problematisch eingeordnet.
| Diagnose | Idee |
|---|---|
| Korrelationskoeffizient bzw. Korrelationsmatrix | Hohe Korrelationen zwischen unabhängigen Variablen sichtbar machen. |
| VIF | Erklärt eine unabhängige Variable durch die anderen und misst Varianzinflation. |
| Konditionszahl κ | Bei mehreren Variablen Analyse der Korrelationsmatrix; ab ca. 30 problematisch. |
Behandlung: problematische Variablen entfernen, zusammenfassen, weiter zerlegen oder alternative Schätzverfahren wie Ridge-Regression einsetzen.
11.2 Endogenität
Endogenität entsteht, wenn eine unabhängige Variable mit dem Störterm korreliert. Dann ist der Schätzer verzerrt und nicht mehr erwartungstreu. Anders als zufälliger Schätzfehler verschwindet dieser Bias nicht automatisch bei größerer Stichprobe.
ε enthält alle nicht modellierten Einflüsse auf die abhängige Variable.
Im Bildungs-Gehalts-Beispiel verursacht „Ability“ ein Omitted-Variable-Problem: Fähigkeit beeinflusst Bildung und Gehalt. Fehlt diese Variable, landet sie im Störterm und korreliert mit Bildung.

| Lösung | Voraussetzung | Grenze |
|---|---|---|
| Problemvariable kontrollieren | Daten zur omitted variable liegen vor. | Nur möglich, wenn die relevante Variable beobachtet wurde. |
| Instrumentalvariable | Instrument ist relevant und exogen. | Kausale Interpretation nur für die instrumentierte Variable und nur bei gültigem Instrument. |
11.3 Overfitting, Ridge, Lasso und Elastic Net
Overfitting entsteht, wenn Modellwahl, Variablentransformationen oder Algorithmusparameter zu stark an die Stichprobe angepasst werden. Bei Regressionen passiert das besonders leicht, wenn Variablen solange ausgetauscht werden, bis gewünschte p-Werte erscheinen.
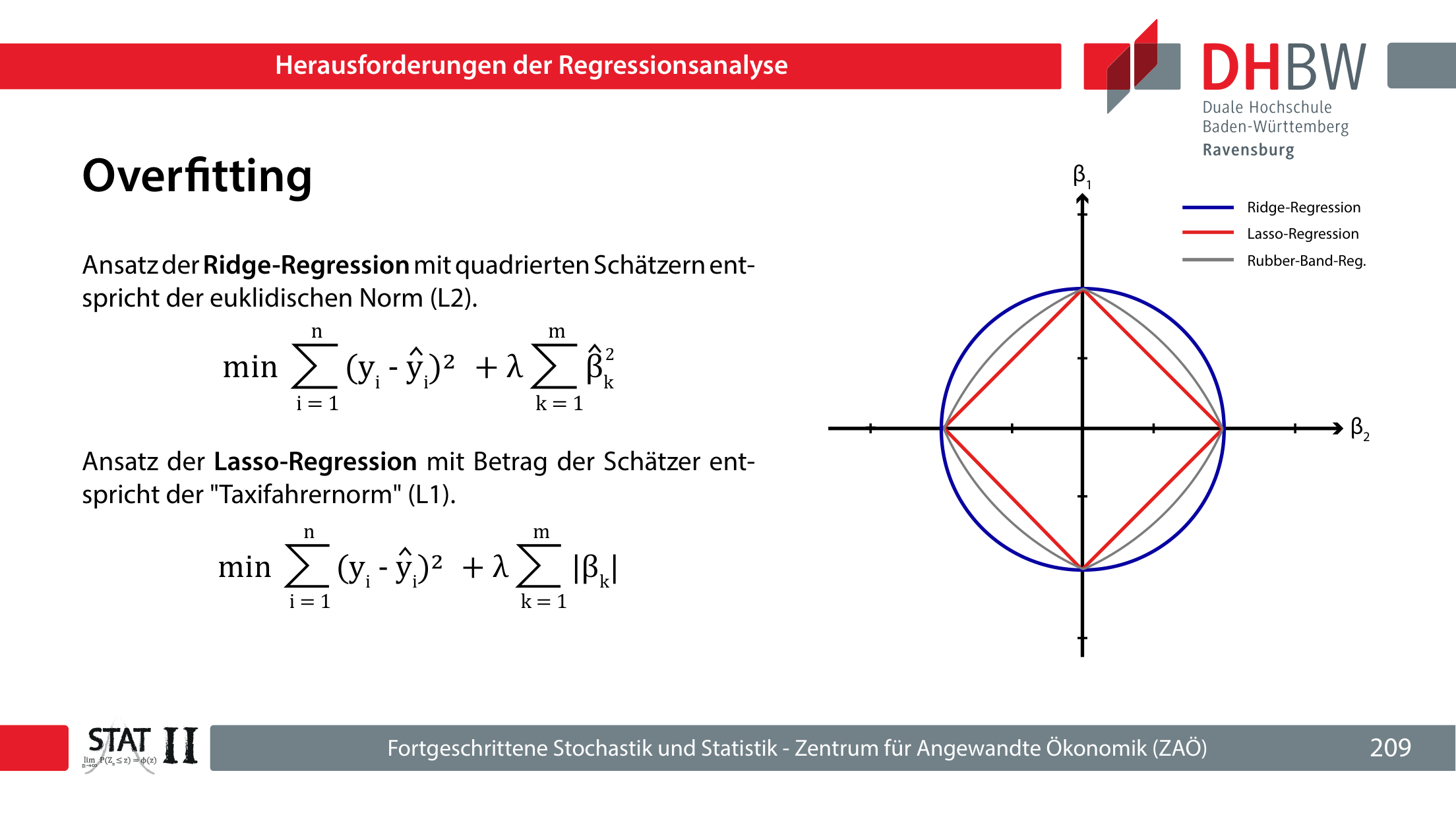
Schrumpft Koeffizienten, entfernt Variablen selten komplett; gut gegen Overfitting und Multikollinearität.
Kann Koeffizienten auf 0 setzen; gut für Variablenselektion.
Verbindet Ridge- und Lasso-Strafe. Die Strafparameter werden sinnvollerweise per k-fold-Cross-Validation gewählt.
12. Maximum-Likelihood-Schätzung
12.1 Grundidee
Maximum Likelihood schätzt Parameter einer angenommenen Verteilung so, dass die beobachtete Stichprobe unter dieser Verteilung möglichst wahrscheinlich ist. Dazu wird angenommen, dass die Beobachtungen unabhängig und identisch verteilt sind, also i.i.d.
- θ
- Parametervektor der angenommenen Verteilung.
- φθ
- Dichte oder Wahrscheinlichkeitsfunktion mit Parametern θ.
- xi
- Beobachtungen der Stichprobe.
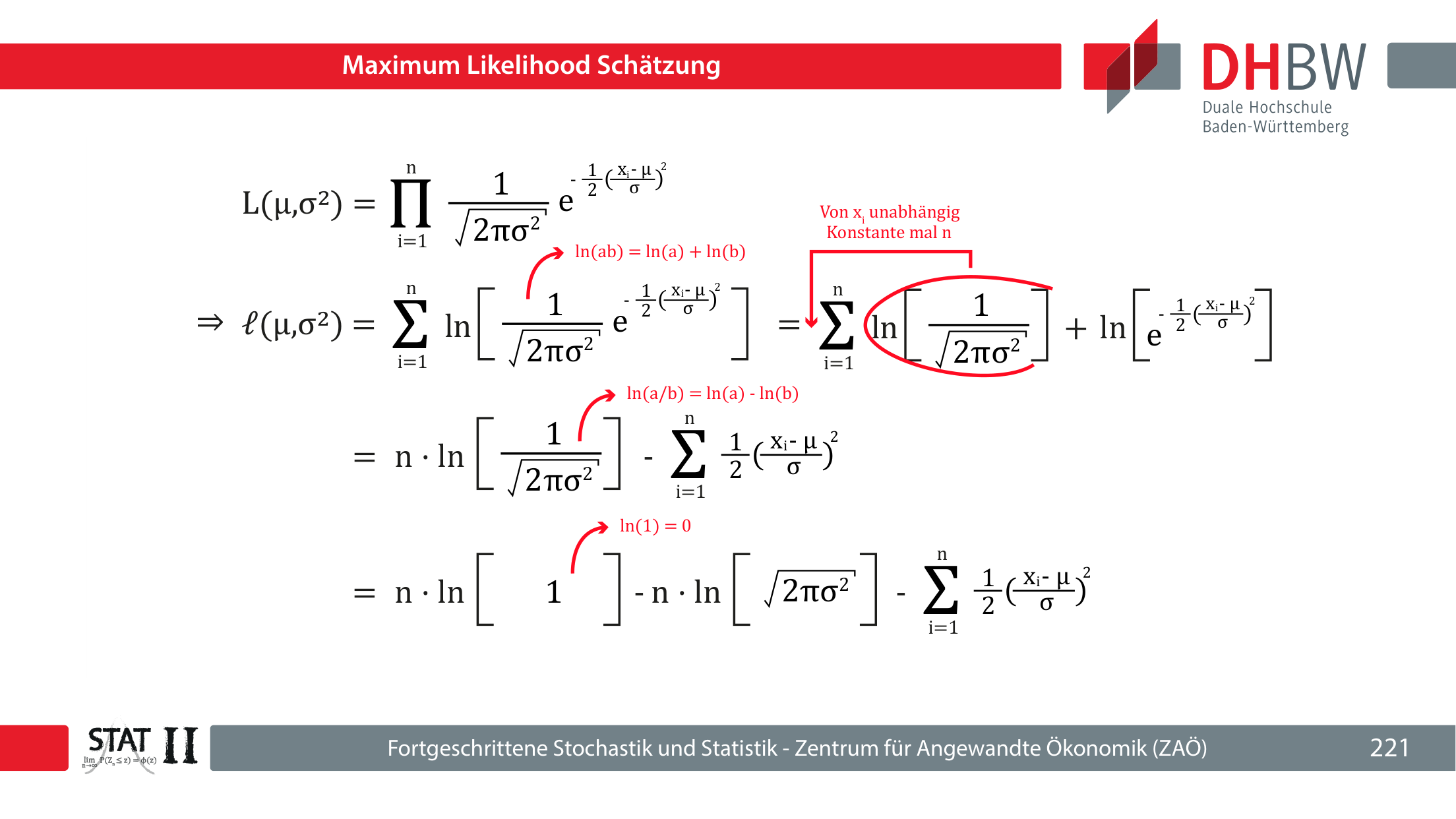
Produkte vieler kleiner Wahrscheinlichkeiten sind numerisch und algebraisch unhandlich. Deshalb wird mit der Log-Likelihood gearbeitet. Aus Produkten werden Summen.
Je näher die Log-Likelihood an 0 liegt, desto besser passt das Modell im Vergleich zu Alternativen. Der absolute Wert allein hat keinen einfachen Qualitätsmaßstab.
12.2 Optimierung und Output
Die ML-Schätzer erhält man durch Optimierung der Log-Likelihood. Analytisch werden die partiellen Ableitungen auf 0 gesetzt und die Hessematrix geprüft. Praktisch liefern Softwarepakete Schätzer, Standardfehler, Log-Likelihood sowie Informationskriterien.
| Ausgabe | Bedeutung | Interpretation |
|---|---|---|
| Parameter-Schätzer | Werte, die die Stichprobe am plausibelsten machen. | Im Binomialbeispiel wird etwa die Trefferwahrscheinlichkeit geschätzt. |
| Standardfehler | Unsicherheit des Schätzers. | Großer Standardfehler bedeutet hohe Schätzunsicherheit. |
| Log-Likelihood | Wert der Zielfunktion am Optimum. | Zum Modellvergleich geeignet, nicht als isolierte Gütenorm. |
| AIC | AIC = -2ℓ + 2k | Bestraft zusätzliche Parameter. |
| BIC | BIC = -2ℓ + k·ln(n) | Bestraft Parameter stärker bei größeren Stichproben. |
13. Codebeispiele aus den Notebooks
Die folgenden Ausschnitte stammen aus den Jupyter Notebooks im Ordner temp_statistik2. Sie sind bewusst kurz gehalten; Variablen wie data, calls, N oder delta werden in den jeweiligen Notebooks vorher geladen bzw. berechnet. In der Klausur ist wichtig, die statistische Fragestellung, den passenden Test und die Interpretation des Outputs zu verstehen; die Software nimmt nur die Rechenarbeit ab.
13.1 Verteilungen mit SciPy
Das Notebook Verteilungen.ipynb nutzt scipy.stats für Wahrscheinlichkeitsfunktionen, Verteilungsfunktionen, Zufallszahlen und Parameterschätzung.
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
# Binomialverteilung: genau 4 Treffer aus 5 Versuchen bei p = 0.75
stats.binom.pmf(k=4, n=5, p=0.75)
# Poisson-Verteilung: genau 4 Ereignisse bei lambda = 1.5
stats.poisson.pmf(k=4, mu=1.5)Für die Darts-Aufgabe wird die einzelne Trefferwahrscheinlichkeit aus beobachteten Trefferzahlen geschätzt und danach für mehrere Fragestellungen verwendet.
hits = [1,2,1,1,2,3,0,3,2,0,3,2,1,2,3,3,2,1,0,3,2,1,1,2]
p = stats.fit(stats.binom, hits, bounds={"n": [3, 3]}).params.p
1 - stats.binom.cdf(k=1, n=3, p=p) # mindestens zwei T20
stats.binom.pmf(k=3, n=3, p=p) # 180er
stats.binom.pmf(k=9, n=9, p=p) # neun perfekte DartsFür die Hotline-Aufgabe werden Poisson-Verteilung und Exponentialverteilung kombiniert: Anzahl der Anrufe pro Stunde vs. Wartezeit zwischen Anrufen.
lam = np.mean(calls["calls"])
stats.poisson.pmf(k=0, mu=lam) # kein Anruf in einer Stunde
1 - stats.poisson.cdf(k=4, mu=lam) # mindestens 5 Anrufe
# scale ist bei scipy.stats.expon der Kehrwert von lambda
stats.expon.cdf(5/60, loc=0, scale=1/lam) # Pause maximal 5 Minuten
1 - stats.expon.cdf(30/60, loc=0, scale=1/lam) # Pause mindestens 30 Minuten13.2 Z-Test
Das Z-Test-Notebook berechnet zuerst den Standardfehler des Mittelwerts und setzt die beobachtete Abweichung in Standardabweichungseinheiten.
import numpy as np
import scipy.stats as stats
variance = 2.91 / N
sigma = np.sqrt(variance)
z = delta / sigma
# einseitiger linksseitiger Test
p = stats.norm.cdf(z)
# zweiseitiger Test bei negativer Abweichung
p = 2 * stats.norm.cdf(z)stats.norm.cdf(z), 1 - stats.norm.cdf(z) oder die doppelte Fläche passt, entscheidet die Alternativhypothese.
13.3 t-Tests mit Pingouin und von Hand
Die t-Test-Notebooks verwenden pingouin für fertige Tests. Der Einstichproben-t-Test ersetzt die zweite Stichprobe durch den Sollwert.
import pingouin as pg
# Einstichproben-t-Test: Ist der Mittelwert von Alt gleich 4.00?
pg.ttest(data["Alt"], 4.00)Der gleiche p-Wert lässt sich über Standardfehler, t-Wert und t-Verteilung nachvollziehen.
stdErr = np.std(data["Alt"], ddof=1) / np.sqrt(len(data["Alt"]))
t_value = (np.mean(data["Alt"]) - 4.00) / stdErr
from scipy.stats import t
prob = t.cdf(t_value, df=len(data["Alt"]) - 1)
p = (1 - prob) * 2 # zweiseitiger Test
round(p, 4)Beim Zweistichproben-t-Test ist die Paarung entscheidend. Studiengänge sind ungepaart; Marketing und Analysis sind gepaart, weil dieselben Personen verglichen werden.
wi = data.loc[data["Kurs"] == "Wirtschaftsinformatik", "Punkte"]
ds = data.loc[data["Kurs"] == "Data Science", "Punkte"]
pg.ttest(wi, ds)
mkt = data.loc[data["Vorlesung"] == "Marketing", "Punkte"]
ana = data.loc[data["Vorlesung"] == "Analysis", "Punkte"]
pg.ttest(mkt, ana, paired=True)13.4 ANOVA und Post-Hoc-Tests
Das ANOVA-Notebook formt die Daten zuerst ins lange Format. Danach prüft die ANOVA, ob mindestens ein Bot-Mittelwert abweicht.
data = data.melt(
id_vars=["Arbeit"],
value_vars=["Bot_A", "Bot_B", "Bot_C", "Bot_D"],
var_name="Bot",
value_name="Accuracy",
)
aov = pg.anova(dv="Accuracy", between="Bot", data=data, detailed=True)
aovWenn die ANOVA signifikant ist, folgen Paarvergleiche.
from statsmodels.stats.multicomp import pairwise_tukeyhsd
tukey = pairwise_tukeyhsd(endog=data["Accuracy"], groups=data["Bot"], alpha=0.05)
print(tukey)
games_howell = pg.pairwise_gameshowell(dv="Accuracy", between="Bot", data=data)
print(games_howell)
pairwise_ttest = pg.pairwise_tests(
dv="Accuracy",
between="Bot",
data=data,
padjust="bonferroni",
)
print(pairwise_ttest)13.5 Normalität prüfen
Das Normalitäts-Notebook kombiniert visuelle Prüfung per Q-Q-Plot und formale Tests. Die Nullhypothese lautet jeweils: Die Daten folgen der geprüften Verteilung.
stats.probplot(data, dist="norm", plot=plt)
plt.title("Q-Q Plot")
plt.show()
stats.shapiro(data)
mu, std = stats.norm.fit(data)
stats.kstest(data, stats.norm.cdf, args=(mu, std))
stats.anderson(data, dist="norm")13.6 Chi-Quadrat-Tests
Der Unabhängigkeitstest kann direkt auf einer Kontingenztabelle laufen oder auf langen Daten mit pingouin.
from scipy.stats import chi2_contingency
chi2_stat, p_value, dof, expected = chi2_contingency(values)
p_valuedata = pd.read_excel("Werbemailings.xlsx", usecols="B:D", skiprows=26)
data = pd.melt(data, value_vars=["Newsletter A", "Newsletter B", "Newsletter C"])
data = data.loc[data["variable"] != "Newsletter C", :]
expected, actual, result = pg.chi2_independence(
data,
"variable",
"value",
correction=True,
)
print(actual)
print(expected)
resultDer Anpassungstest vergleicht beobachtete Häufigkeiten mit einer erwarteten Verteilung. Die erwarteten Häufigkeiten werden vorher auf dieselbe Gesamtzahl normiert.
from scipy.stats import chisquare
observed = np.array([20, 25, 10])
expected = np.array([200, 300, 40])
expected = expected * (observed.sum() / expected.sum())
chi2_stat, p_value = chisquare(f_obs=observed, f_exp=expected)
p_value13.7 OLS-Regression mit Statsmodels
Die OLS-Notebooks verwenden die Formel-API von statsmodels. Sie ist gut lesbar, weil die Modellgleichung fast wie die mathematische Spezifikation aussieht.
import statsmodels.formula.api as smf
model = smf.ols("Punkte ~ Lernstunden", data=data).fit()
print(model.summary())
print(model.conf_int(alpha=0.05))Im Strommarkt-Notebook zeigt der Vergleich zweier Formeln, dass Modellrichtung und Kontrollvariablen fachlich begründet werden müssen.
# Einfaches, fachlich problematisches Modell
model = smf.ols("Netzlast ~ Preis", data=data).fit()
print(model.summary())
# Plausibleres Modell: Preis als abhängige Variable
model = smf.ols("Preis ~ Netzlast + GesamtEE", data=data).fit()
print(model.summary())
print(model.conf_int(alpha=0.05))Das Mensa-Notebook zeigt eine multiple Regression mit kategorialen und numerischen Prädiktoren. Kategoriale Variablen werden von statsmodels über die Formel intern dummy-codiert.
model = smf.ols(
"food_score ~ gender + status + preference + allergy + ambience_score + service_score",
data=data,
).fit()
print(model.summary())13.8 Endogenität und zweistufige IV-Schätzung
Das Endogenitäts-Notebook simuliert das Omitted-Variable-Problem und zeigt eine einfache zweistufige Instrumentalvariablenlogik. In der ersten Stufe wird die endogene Variable durch das Instrument erklärt; in der zweiten Stufe wird mit den gefitteten Werten weitergearbeitet.
model1 = smf.ols("education ~ availability", data=data).fit()
instrument = model1.fittedvalues
model2 = smf.ols("wage ~ instrument", data=data).fit()
beta.append(model2.params["instrument"])summary(), p-Werte und Konfidenzintervalle beantworten statistische Fragen. Die kausale Frage beantwortet der Code nicht allein; dafür müssen Modellannahmen, Kontrollvariablen oder Instrumente fachlich tragfähig sein.
13.9 Maximum Likelihood als Optimierung
Das Verteilungsnotebook zeigt Maximum Likelihood am Poisson-Parameter. Optimiert wird die negative Log-Likelihood, weil Minimierer in SciPy standardmäßig minimieren.
from scipy.optimize import minimize
def neg_log_likelihood(lmbda):
return -np.sum(stats.poisson.logpmf(x, mu=lmbda))
initial_guess = np.mean(x)
result = minimize(
neg_log_likelihood,
x0=initial_guess,
method="L-BFGS-B",
bounds=[(0.0001, None)],
)
lambda_mle = result.x[0]
log_likelihood = -result.fun14. Klausurstrategie, Checkliste und mögliche Fragen
13.1 Rechen- und Interpretationsschema
- Variable identifizieren: numerisch oder kategorial, diskret oder kontinuierlich, eine oder mehrere Gruppen.
- Verteilung oder Testfamilie auswählen: Binomial, Poisson, Exponential, Normal, t-Test, ANOVA, Chi-Quadrat, OLS oder ML.
- Hypothesenpaar sauber formulieren, inklusive Richtung bei einseitigen Tests.
- Teststatistik, p-Wert und Konfidenzintervall nicht nur berechnen, sondern in Worten interpretieren.
- Annahmen prüfen: Normalität, Paarung, Unabhängigkeit, erwartete Häufigkeiten, Homoskedastizität, Multikollinearität, Endogenität.
- Grenzen benennen: Signifikanz ist nicht Effektgröße, Korrelation ist nicht Kausalität, kleine Stichproben liefern unsichere Tests.
13.2 Kompakte Lerncheckliste
| Kann ich ...? | Selbsttest |
|---|---|
| Diskrete und kontinuierliche Verteilungen unterscheiden? | Erkläre, warum P(X=x)=0 bei kontinuierlichen Verteilungen kein Widerspruch ist. |
| Erwartungswert und Varianz korrekt berechnen? | Rechne Würfel, Gleichverteilung auf [0,1] und Glücksrad nach. |
| Binomial, Poisson und Exponential sicher zuordnen? | Trefferzahl, Ereigniszahl pro Stunde und Wartezeit voneinander trennen. |
| ZGS und Standardfehler erklären? | Begründe, warum die Varianz des Mittelwerts σ2/n ist. |
| p-Werte korrekt formulieren? | Formuliere jeden p-Wert als Wahrscheinlichkeit unter Gültigkeit von H0. |
| Gepaarte und nicht gepaarte t-Tests unterscheiden? | Prüfe, ob dieselbe Person/Einheit zweimal gemessen wurde. |
| ANOVA und Post-Hoc-Tests trennen? | Sage, warum ANOVA allein keine konkrete Paarung nennt. |
| Chi-Quadrat-Tests richtig einsetzen? | Unabhängigkeit zweier Merkmale vs. Anpassung an Sollverteilung unterscheiden. |
| OLS-Output interpretieren? | Schätzer, Standardfehler, p-Wert, Konfidenzintervall und R2 in einem Satz erklären. |
| Regressionsprobleme erkennen? | Multikollinearität, Endogenität und Overfitting jeweils mit Ursache und Folge nennen. |
| ML-Schätzung verstehen? | Erkläre, warum aus der Likelihood durch Logarithmus eine Summe wird und wozu AIC/BIC dienen. |
13.3 Mögliche Klausurfragen
- Eine Hotline erhält im Mittel 2,5 Anrufe pro Stunde. Welche Verteilung beschreibt die Anzahl der Anrufe, welche die Wartezeit bis zum nächsten Anruf?
- Berechne Erwartungswert und Varianz einer Gleichverteilung auf [2,4] und interpretiere beide Werte.
- Ein Würfel wird 10.000-mal geworfen und zeigt einen deutlich zu niedrigen Mittelwert. Formuliere H0, H1, Teststatistik und p-Wert-Interpretation.
- Warum kann ein zweiseitiger Test einen anderen p-Wert liefern als ein linksseitiger Test mit derselben Teststatistik?
- Wann ist ein t-Test gepaart? Gib ein Beispiel und erkläre, was dann getestet wird.
- Eine ANOVA ist signifikant. Warum brauchst du danach einen Post-Hoc-Test?
- Ein Normalitätstest liefert p=0,12. Was darfst du sagen, was nicht?
- Bei einem Werbemailing unterscheiden sich Öffnungsraten deskriptiv. Welcher Chi-Quadrat-Test passt und wie lautet H0?
- Interpretiere einen OLS-Koeffizienten mit Standardfehler, p-Wert und Konfidenzintervall in korrekter Sprache.
- Warum kann ein hochsignifikanter Strompreis-Koeffizient fachlich trotzdem falsch interpretiert sein?
- Wie erkennt und behandelt man Multikollinearität?
- Was ist ein gültiges Instrument bei IV-Schätzung, und warum reichen Relevanz oder Exogenität allein nicht?
- Vergleiche Ridge und Lasso: Zielfunktion, Effekt auf Koeffizienten und typische Anwendung.
- Erkläre Likelihood, Log-Likelihood, AIC und BIC an einem Verteilungsfit.
15. Abdeckung des Foliensatzes
| Folie/Kapitel | Inhalt | In Zusammenfassung enthalten? | Wo behandelt? |
|---|---|---|---|
| 1-3 | Titel, Vorwort, Inhaltsverzeichnis | Ja, als Quelle und Gesamtgliederung | Header, Überblick |
| 4-8 | Zufallsvariablen, Ereignismenge, diskret/kontinuierlich, Funktionsarten | Ja | Kapitel 2 |
| 9-14 | Diskrete Verteilungen, Wahrscheinlichkeitsfunktion, Verteilungsfunktion, Summation | Ja | Kapitel 2.2 |
| 15-21 | Kontinuierliche Verteilungen, Dichte, Integrale, Ableitung | Ja | Kapitel 2.3 |
| 22-31 | Erwartungswert diskret/kontinuierlich, Linearität, Übungen Glücksrad/Zufallsgenerator | Ja | Kapitel 3.1, Aufgabenhinweise |
| 32-41 | Varianz, Standardabweichung, Additivität, Roulette-/Glücksradbeispiele | Ja | Kapitel 3.2 |
| 42-44 | Momente, Schiefe, Wölbung/Exzess | Ja | Kapitel 3.3 |
| 45-47 | Gleichverteilung, Erwartungswert, Varianzherleitung | Ja | Kapitel 4.1 |
| 48-53 | Binomialverteilung, Fakultät, Binomialkoeffizient, Erwartungswert/Varianz | Ja | Kapitel 4.2 |
| 54-59 | Poisson-Verteilung, Grenzwert zur Binomialverteilung, Erwartungswert/Varianz | Ja | Kapitel 4.3 |
| 60-64 | Exponentialverteilung, Verteilungsfunktion, Momente, Gedächtnislosigkeit | Ja | Kapitel 4.4 |
| 65-67 | Darts- und Hotline-Modellierungsübungen | Ja, als typische Aufgabenlogik | Kapitel 4, Kapitel 13 |
| 68-69 | Normalverteilung | Ja | Kapitel 5.1 |
| 70-76 | Zentraler Grenzwertsatz, Normalbereiche, Faustregeln | Ja | Kapitel 5.2 |
| 77-91 | Induktive Statistik, Z-Test, einseitig/zweiseitig, Würfel- und Roulettebeispiele | Ja | Kapitel 6.1-6.2 |
| 92-98 | Statistische Testarten und Testauswahl | Ja | Kapitel 6.3 |
| 99-113 | Zweistichproben-t-Test, gepaart/nicht gepaart, p-Wert, Konfidenzintervall | Ja | Kapitel 7.1-7.3 |
| 114-124 | Einstichproben-t-Test, t-Verteilung, Freiheitsgrade, Mensaübung | Ja | Kapitel 7.1-7.3, Kapitel 13 |
| 125-128 | ANOVA und Post-Hoc-Tests | Ja | Kapitel 7.4 |
| 129-141 | Parametrische Tests, Normalität, Q-Q-Plot, Normalitätstests, Sensitivität/Spezifität | Ja | Kapitel 8.1-8.2 |
| 142-147 | Chi-Quadrat-Unabhängigkeitstest, Werbemailing | Ja | Kapitel 9.1 |
| 148-151 | Chi-Quadrat-Anpassungstest, Mensaübung | Ja | Kapitel 9.2, Kapitel 13 |
| 152-153 | Fehler erster/zweiter Art, Daten- und Modellfehler | Ja | Kapitel 8.3 |
| 154-169 | Regressionsarten, OLS, Residuen, Output, p-Wert, Konfidenzintervall, R2 | Ja | Kapitel 10.1-10.5 |
| 170-181 | Strommarktbeispiel, Modellrichtung, Interpretation, Mensa-OLS-Übung | Ja | Kapitel 10.4, Kapitel 13 |
| 182-183 | Erweiterungen und Baustellen der Regression | Ja | Kapitel 11 |
| 184-193 | Multikollinearität, Bias/Schätzfehler, VIF, Konditionszahl, Behandlung | Ja | Kapitel 11.1 |
| 194-204 | Endogenität, omitted variables, Instrumentalvariablen, zweistufige Regression | Ja | Kapitel 11.2 |
| 205-214 | Overfitting, Ridge, Lasso, Elastic Net, Cross-Validation, Bias-Variance-Tradeoff | Ja | Kapitel 11.3 |
| 215-225 | Maximum-Likelihood-Schätzung, Log-Likelihood, Optimierung, Standardfehler, AIC/BIC | Ja | Kapitel 12 |